Minimizing React hydration with @plasmicapp/saturated
- Authors

- @chungwu
- Last updated
The cost of React hydration is the source of many headaches for multi-page apps that are using frameworks like Next.js. If your site has mostly-static content with a few islands of interactivity, you are paying a cost in terms of larger Javascript bundle size, higher total blocking time, and longer time to interactive. But what can you do about it?
At Plasmic, we build a visual builder for React sites and applications, and we spend a lot of time thinking about performance. I had recently been deep-diving into React Server Components, and I wondered — could we apply some of the same ideas to minimize hydration costs, outside of server components?
- What is hydration?
- Why is hydration expensive?
- What can we do about hydration?
- That one weird trick to skip hydration
- Introducing
- Flattening static content
- Preserving hydration for client components
- Detecting client components that require hydration
- Sending the saturated element to the browser
- Putting this all together...
- So... does it work?
- But is this a practical solution?
What is hydration?
Frameworks like Next.js models your site as a React application, with each page being a React component. However, unlike typical single-page apps, where rendering happens almost exclusively in the browser, multi-page frameworks typically do this song and dance to render each page:
- When the browser requests a page, the server performs “server-side rendering” by constructing a React tree of the requested page, and rendering it into static HTML (this could also have been done and cached at build time).
- Once the browser receives the response, it can immediately start parsing and rendering the raw HTML and CSS, well before any Javascript has been received and executed. However, because this is just HTML and CSS, this content is not interactive; no event handlers have been attached, and no state is being tracked yet.
- Some bootstrapping Javascript is loaded and performs hydration. Hydration works similarly to normal React rendering - it constructs the React tree to render, but instead of creating new DOM elements to add to the document, it attaches to the existing DOM that’s already part of the initial HTML. It is here where event handlers from your React components actually get installed, React states initialized, effects fired, etc.
Once hydration finishes, you end up with a fully working React application, as if you rendered it from scratch. The application will respond to events, update states, and re-render as you’d expect. The server-side-rendering + hydration is just a “trick” for getting content to show up in the browser as quickly as possible, before Javascript is loaded and ready.
Why is hydration expensive?
For hydration to run, you need not only the bootstrapping Javascript (including React itself), but also the code for all your React components that make up the React tree. That means a lot of code needs to be downloaded, and then executed, to rebuild your React application in the browser.
What makes this worse is that, for many websites and landing pages, a lot of the page content is just static text and images, without any fancy interactivity or state. For these parts of the page, you actually really only needed the initial HTML and CSS, and it is unnecessary and wasteful to be reconstructing a huge virtual tree in React only to do nothing useful with it.
Can you somehow only hydrate the parts of your page that are interactive? Not generally. For React, hydration always happens top-down; to hydrate a component element, you must first hydrate its parent, and so on. This is fundamental to the programming model of React. For example, a component like <TextInput /> might take in an onChange event listener as a prop. To hydrate that <TextInput />, you need to get your hands on that onChange function, but that function was created by its parent element (say, the <Form /> element) in its render function, so to get that handler function, you must first hydrate the <Form /> element and run its render function. But the <Form /> element may also take in some other props from its parent, and so on.
What can we do about hydration?
This is an exciting area of research, and there are many different efforts underway tackling this general class of problems outside of React. qwik is rethinking things from the ground up to make it possible to hydrate from anywhere in the tree, not always from the top. Marko and Astro are making it possible to only hydrate the sub-trees of the page that require interactivity, and giving you more control over when hydration happens. If you are interested in learning more on this topic, just read everything that Ryan Carniato has written; here’s a great overview to start with.
What if you want to stick with React? In React 18, streaming server-side rendering and selective hydration make it possible to incrementally hydrate while HTML is being downloaded. And server components move the rendering of some components to the server, so that you don’t need to download and run the code for those components in the browser at all (though you’ll still end up hydrating server-rendered base HTML elements in the browser). This can be a potent combination, but it is not quite ready for prime time yet.
That one weird trick to skip hydration
For as long as hydration has existed, people have been trying to hack around it. One trick that comes up often is your friendly neighborhood dangerouslySetInnerHTML prop:
<div
dangerouslySetInnerHTML={{
__html: `<strong>bahaha</strong> can't hydrate <em>this!</em>`,
}}
/>
This prop is an escape hatch for rendering some arbitrary HTML in an element. React does not attempt to understand what’s in the HTML blob; during hydration, it just happily skips over it.
So… What if you can take your giant React element tree, identify the subtrees that are completely “static”, and convert each static subtree into a single element with dangerouslySetInnerHTML? You will end up with a much smaller tree, React wouldn’t need to do anything to hydrate those parts of the page, and you’ll significantly lower the cost of hydration. Win!
Introducing @plasmicapp/saturated
I explore this idea further, in a very experimental-for-the-mad-scientist-in-you package @plasmicapp/saturated, where given a React element, we return a new React element with as much of the original tree as possible converted to static HTML “automatically”-ish. I call this process “saturation”, because once you’re saturated, you don’t need hydration anymore… 😎
The overall strategy is this: we’re going to try to “render” this initial React element, like <Page />, into a tree of base HTML elements as much as possible. Then, starting from the leaves, we check if each base HTML element can be “saturated”; simply, if it doesn’t have any event handlers (onClick, etc), it can be saturated. We do this recursively — a base HTML element can be saturated if it doesn’t have any illegal props, and all its children can be saturated as well.
// This...
<div className="greetings">
<h1>Hello world!</h1>
<div>Happy to see you too</div>
</div>
// Can be turned into...
<div className="greetings" dangerouslySetInnerHTML={{__html: `
<h1>Hello world!</h1>
<div>Happy to see you too</div>
`}} />
But what happens if we encounter a component? We need to try to “render” this component into base HTML tags too, so we can see if we can inline parts of it. In this proof-of-concept, we “render” this component the lazy way — since React components are just functions that produce more React elements, we can just call the component with its props to “render” it!
function Greeting({name}) {
return <div className="greet">Hello {name}!</div>;
}
// This...
<Greeting name="Pikachu" />
// can be turned into...
<div className="greet" dangerouslySetInnerHTML={{__html: `
Hello Pikachu!
`}} />
Incidentally, this is similar to how React server components “render away” server components, leaving only client components and base HTML elements in the tree. But not every React component can be “rendered away” like this — for example, some components may be creating event handlers that are installed onto DOM elements, so they must be preserved and run on the browser to do that work. We will also refer to these components that we must preserve for the browser as “client components”.
At the end of this process, we should end up with a React element tree composed of only base HTML elements, plus these detected “client component” elements. Hopefully this is a much smaller tree than the one that we started with, and will hydrate much faster!
Note that this optimization is happening at run time — that is, we’re dealing with an actual React element, and not source files. We’re not statically analyzing source code and transforming components, which is a much harder problem. Instead, we focus on this: given that we’re going to render <Page props=... />, how do we make it hydrate as quickly as possible in the browser? We only care about optimizing this specific page component element with these specific props, and not trying to optimize the component in general.
Let’s see how far we can push this!
Flattening static content
In the easiest case, we are just outputting static content. There are no event handlers, no React hooks. We should be able to do this easily!
function Page({pokemons}) {
return (
<div>
{pokemons.map(pokemon => <PokemonCard pokemon={pokemon} />)}
</div>
);
}
function PokemonCard({pokemon}) {
return (
<div className="card">
<div className="title">{pokemon.name}</div>
<div>{pokemon.types.map(t => <Chip text={t} />)}</div>
</div>
);
}
function Chip({text}) {
return <span className="chip">{text}</span>
}
// We should be able to convert this React element...
<Page
pokemons={[{
slug: "pikachu",
name: "Pikachu",
types: ["Electric"]
}, {
slug: "bulbasaur",
name: "Bulbasaur",
types: ["Grass", "Poison"]
}]}
/>
// into this element...
<div dangerouslySetInnerHTML={{__html: `
<div class="card">
<div class="title">Pikachu</div>
<div><span class="chip">Electric</span></div>
</div>
<div class="card">
<div class="title">Bulbasaur</div>
<div><span class="chip">Grass</span><span class="chip">Poison</span></div>
</div>
`}} />
Preserving hydration for client components
But… How many of your components render truly static content that requires no Javascript? In Next.js, even the humble <Link /> component requires Javascript to enable instantaneous page transition, and it would be a shame to render it as a static <a/> link and forgo those benefits.
// Suppose our PokemonCard component now contains a Link.
// Even though this component is mostly static content,
// we can't just turn it into a
// <div dangerouslySetInnerHTML=.../> because we want to
// hydrate that <Link /> component...
function PokemonCard({ pokemon }) {
return (
<div className="card">
<div className="title">{pokemon.name}</div>
<div>
{pokemon.types.map((t) => (
<Chip text={t} />
))}
</div>
<Link href={`/p/${pokemon.slug}`}>
<a>Read more</a>
</Link>
</div>
)
}
Bummer. Now we can’t turn the whole page into static HTML because of the <Link /> components we want to hydrate. But we can still do our best, and turn the page into this:
<div>
<div className="card">
<div dSIH={{ __html: `Pikachu` }} className="title" />
<div dSIH={{ __html: `<span class="chip">Electric</span>` }} />
<Link href={`/p/pikachu`}>
<a dSIH={{ __html: 'Read more' }} />
</Link>
</div>
<div className="card">
<div dSIH={{ __html: `Bulbasaur` }} className="title" />
<div dSIH={{ __html: `<span class="chip">Grass</span><span class="chip">Poison</span>` }} />
<Link href={`/p/bulbasaur`}>
<a dSIH={{ __html: 'Read more' }} />
</Link>
</div>
</div>
Note what we are doing here — whenever we detect that there’s a component that needs to be hydrated, its path to the root must also be hydrated, but all other parts of the tree can still be static and saturated via dangerouslySetInnerHTML. This is exactly what we want for minimal hydration — just thin narrow paths from the root to those client components, with the rest of the tree truncated.
Detecting client components that require hydration
But how do we know if a component can be inlined away, or must be preserved for hydration as a client component? In the above example, we knew we wanted to hydrate <Link/>. But is it also possible to detect this automatically?
Consider: When is it important to run the code for a component?
One obvious case is when components use React hooks like useState and useEffect. These components clearly have behavior and side effects that must be run in the browser to set up a working React application. They are also easy to detect — when we “fake-render” a component by calling it with its props, React will throw an error if any hooks are used outside of the React runtime.
A less obvious case is when components creates functions (often event handlers) that are ultimately attached to base HTML elements. These functions and their closures could only have been created by this component, and so we must run the code for this component.
// An example of the Chip component that CANNOT be inlined and
// must be hydrated, because it is attaching an event handler
// on a DOM element, and that event handler can only be created
// by running this component.
function Chip({ text }) {
return (
<span className="chip" onClick={() => alert(text)}>
{text}
</span>
)
}
It is actually not the case that all components that pass down functions must be client components! For example, these components are perfectly fine to inline away:
function UppercaseChip({text}) {
return <Chip text={text} transformer={t => t.toUpperCase()} />;
}
function Chip({text, transformer}) {
return <span className="chip">{transformer(text)}</span>;
}
// We can turn this:
<UppercaseChip text="hello" />
// into this!
<span className="chip" dSIH={{__html: "HELLO"}} />
That’s because the function passed down is only used for rendering, but not attached to the DOM element; there’s no reason to need the function again once you’re done rendering.
Sending the saturated element to the browser
Great - now we have a cool way of transforming a React element to a “saturated” version, with minimal hydration necessary. But when do we do this saturation?
We can’t do it in the browser, because that would mean we’d be fake-rendering the element tree in the browser, performing all the work we had been hoping to avoid. So we must do it on the server — in getStaticProps() or getServerSideProps() for Next.js. That means we’d have to saturate the page component element, and then turn it into some serializable blob returned from getStaticProps(). Our page component can then deserialize and render the saturated element.
But, how do we turn the saturated React element into something that’s serializable and legal to return as a page prop? We turn again to React Server Components for inspiration! We can call JSON.stringify() on the element with a replacer function that replaces non-serializable parts with reference strings. For example, we could replace a Symbol("react.element") with a special string like "$s$s_react.element". Then, when we need to deserialize, we just call JSON.parse() with a reviver function that looks for those special strings and replace them with real Symbols!
What about references to the actual component function? Each React component element has a type field that references the rendering function, which we cannot JSON.stringify(). We need to replace these function references with a string when we serialize, and then replace them with actual functions again when we deserialize. This is trickier to do. React Server Components accomplish the same feat with a major assist from the bundler, which knows how to lookup client modules by string identifiers, but we don’t have such luxury. Instead, we will have to do this manually — curate a lookup dictionary of string names for known client components, which is available both on the server and in the browser. When serializing on the server, we replace those component functions with string references, and when deserializing on the browser, we can swap out those strings with the real component functions.
Putting this all together…
Here’s how it might look in a Next.js page:
import Header from "../components/header";
import Link from "next/link";
import Head from "next/head";
import {
saturate,
serializeSaturated,
deserializeSaturated
} from "@plasmicapp/saturated";
// Build the lookup dictionary of client components that we
// will need to hydrate in the browser. These will not be
// inlined away.
const KNOWN_CLIENT_COMPONENTS = {
"my-header": Header,
"nextjs-link": Link,
"nextjs-head": Head,
};
export function getStaticProps() {
// saturate our <RealPage_/> element, making sure we do
// not inline away the KNOWN_CLIENT_COMPONENTS
const saturated = saturate(
<RealPage_ />,
{
knownClientRefs: new Set(Object.values(KNOWN_CLIENT_COMPONENTS))
}
);
// Serialize the saturated element into a JSON string, replacing
// known client components with corresponding reference strings.
const saturatedJson = serializeSaturated(
saturated, { knownClientRefs: KNOWN_CLIENT_COMPONENTS }
);
return {
props: { saturatedJson }
};
}
export default function Page({saturatedJson}) {
// Deserialize our saturated JSON string into a React element.
// Note we pass in the same lookup table here, so that
// deserializeSaturated can swap the client components back in.
const element = deserializeSaturated(
saturatedJson, {knownClientRefs: KNOWN_CLIENT_COMPONENTS }
);
return element;
}
function RealPage_() {
// The actual page component that renders page content
return ...;
}
So… does it work?
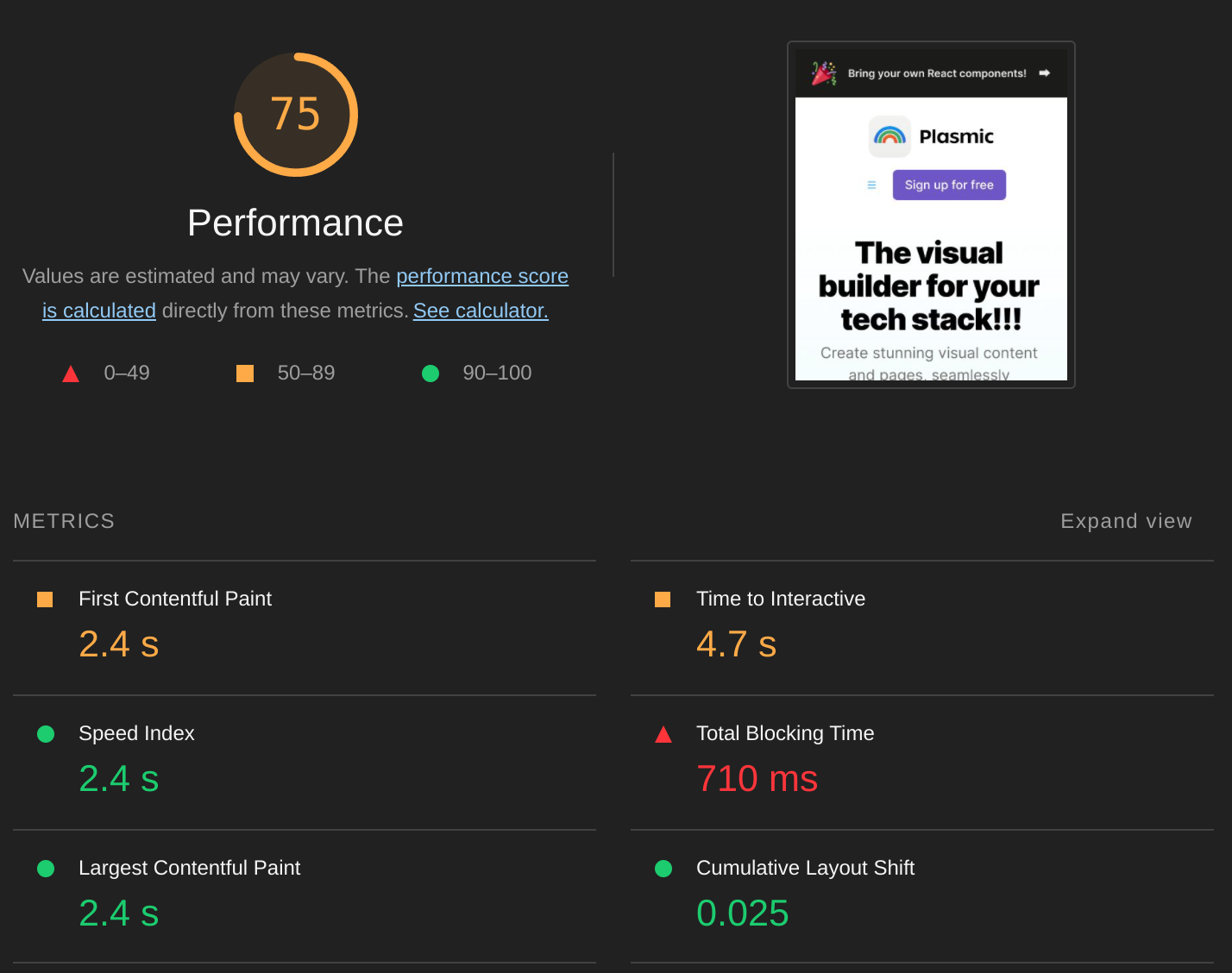
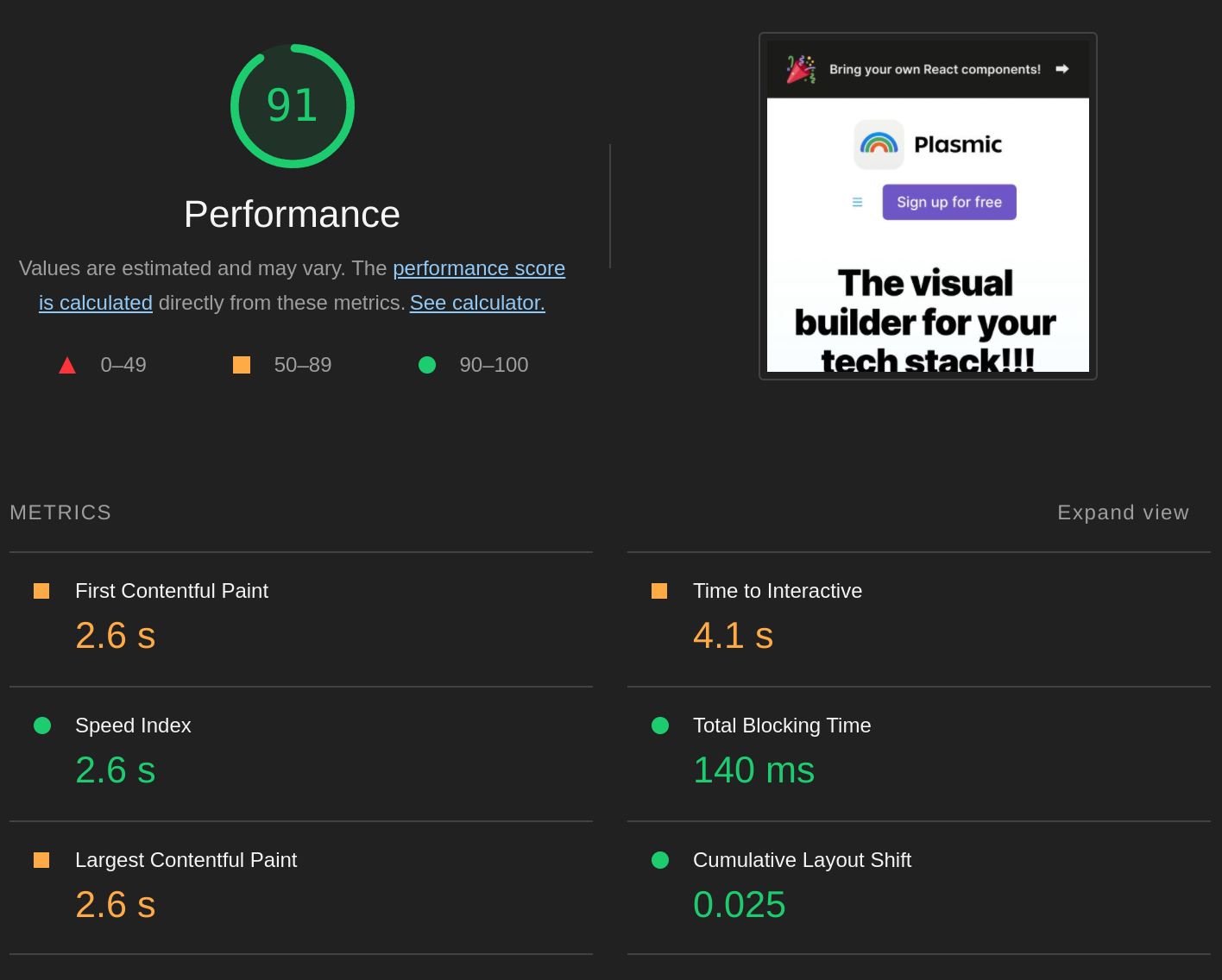
Yes! Running lighthouse on a toy version of the Plasmic home page, a lot of the page could be saturated (shown here as the green bits):

The only parts of the page that are not saturated are the header (which contains Javascript for handling a popover menu in mobile view), and <Link/>s.
Saturating this page resulted in a jump in Lighthouse Mobile score from 75 to 91 — mainly by bringing down total blocking time by 5x!
Before:
After:
But is this a practical solution?
No…? 😅
This proof-of-concept cuts a lot of corners. The “fake-rendering” it does by calling components as functions is not great; it will de-opt whenever it encounters a component that uses any hooks, even though ideally you could still inline components that only use hooks to read static values from a context. And of course, this doesn’t work with <Suspense/> at all. Using a simulated React runtime, similar to how react-ssr-prepass works, could improve the fidelity here.
But even if we improve the rendering simulation, there are a few fundamental flaws to this approach. As you saw above, the developer ergonomics is not great; you need to manually curate a dictionary of client components by running saturate(), and seeing which client components were detected. And even then, because the bundler doesn’t know what we’re up to, we’ll still be sending down the Javascript code for all the React components on this page, even the ones that we have inlined and no longer need. Furthermore, the page props now essentially include a copy of the HTML in its various blobs of dangerouslySetInnerHTML, so you are nearly doubling the HTML document size. The inlined HTML has to be there, because it must be possible to render the whole page using just the page props from scratch — that’s how instantaneous client page transitions work in Next.js. I’m not sure if it’s possible to avoid the flaws above.
The most practical solution to avoiding hydration with the React stack is still server components, which will be ready… soon! But even React 18 already brings great improvements here, like making hydration non-blocking across <Suspense/> boundaries.
Still, I’m excited about the possibilities. And for something like Plasmic, which dynamically downloads React component code to render the designs you’ve built visually in the editor, it could be an especially good fit — Plasmic knows a lot about the components it is rendering, and does have control over what code to send to the browser, and so could conceivably make this trick work automatically.
Anyway, feel free to check out the repo and tell me why it’ll never work 🙂
Follow @plasmicapp on Twitter for the latest updates.